
Be ready to study forever - 개발자 꿈나무
[JPA] JPQL 본문
JPQL이란?)
SQL쿼리가 DB중심이라면 JPQL은 객체가 중심으로 쿼리를 짤 수 있다. JPQL은 내부적으로 SQL방언에 맞게 해석해서 쿼리로 날려준다. 따라서, 특정 데이터베이스 SQL에 의존하지 않는다.
실제 쿼리를 비교해 보면
//검색
String jpql = "select m from Member m where m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class)
.getResultList();
//실행된 SQL
select
m.id as id,
m.age as age,
m.USERNAME as USERNAME,
m.TEAM_ID as TEAM_ID
from
Member m
where
m.age>18
JQPL의 기본문법)
JPQL은 ANSI SQL의 문법을 거의 지원하며 문법 역시 매우 비슷하다.
기본문법
SQL문법과 거의 동일하다. 다만 em.persist(); INSERT하기 때문에 CRUD 중에 INSERT절만 없다.
**[XXX_절]은 옵션
select_문 :: =
select_절
from_절
[where_절]
[groupby_절]
[having_절]
[orderby_절]
update_문 :: = update_절 [where_절]
delete_문 :: = delete_절 [where_절]JPQL 특징
- JPQL 키워드(select, update, from, where등…)은 대소문자 구분없이 사용가능
- 엔티티와 속성은 대소문자를 구분해서 써야함(Member, age)
- 테이블의 이름이 아닌 객체(엔티티)의 이름을 사용(객체 중심의 쿼리)
- 별칭(Alias)는 필수임 – select m from Member as m where m.age > 18
집합/정렬
SQL에서 지원하는 왠만한 집합과 정렬 기능도 제공한다. 예를들면 COUNT(), SUM(), MAX(), AVG(), MIN()등등의 집합과 GROUP BY, HAVING, ORDER BY 정렬기능도 제공한다.
코드로 보면
select
COUNT(m), //회원수 객체를 넣어도 ID식별자를 카운트 하기 때문에 m.id와 같다
SUM(m.age), //나이 합
AVG(m.age), //평균 나이
MAX(m.age), //최대 나이
MIN(m.age) //최소 나이
from Member m
//SQL쿼리처럼 order by, group by, having을 쓰면됨
select m from Member as m where m.age > 18 order by m.age desc
TypeQuery와 Query
- TypedQuery: 반환타입이 명확할 때 사용
- Query: 반환타입이 명확하지 않을 때 사용
예제코드를 보자면
//TypedQuery로 받음(반환타입이 Member로 명확)
TypedQuery<Member> query =
em.createQuery("SELECT m FROM Member m", Member.class);
//Query반환 타입이 명확하지 않음
Query query =
em.createQuery("SELECT m.username, m.age from Member m");
결과조회 API
- query를 날려서 받은 결과가 하나 이상일 경우
query.getResultList() 사용 (결과가 없으면 빈 리스트 반환)
- query를 날려서 받은결과가 하나일 경우
query.getSingleResult() (결과가 없거나, 둘 이상이면 exception을 날린다)
파라미터 바인딩
파라미터 바인딩에는 두가지 방법이 있는데, 이름으로 바인딩 하는경우, 위치로 바인딩 하는 경우 가 있다. 이름으로 바인딩하는 경우를 추천함(쿼리를 바꾸면 위치도 바뀔 수 있기 때문에)
코드로 살펴보면
//이름으로 바인딩
SELECT m FROM Member m where m.username=:username
query.setParameter("username", usernameParam);
//위치로 바인딩(숫자를 이용)
SELECT m FROM Member m where m.username=?1
query.setParameter(1, usernameParam);
프로젝션
SELECT절에 조회할 때 대상을 지정하는 것을 프로젝션이라고 한다. 프로젝션은 엔티티 전체, 스칼라 타입 (엔티티의 개별 필드), 임베디드 타입등이 지정 가능하다.
예를 들면
- SELECT m FROM Member m -> 엔티티 프로젝션
- SELECT m.team FROM Member m -> 엔티티 프로젝션
- SELECT m.address FROM Member m -> 임베디드 타입 프로젝션
- SELECT m.username, m.age FROM Member m -> 스칼라 타입 프로젝션
스칼라타입으로 각 필드를 개별로 또는 묶어서 조회할 경우 값을 바인딩하는 방법이 몇가지 있는데
- Query타입으로 조회 (단일 칼럼을 조회할 경우)
- Query[] 타입으로 조회(2개 이상의 칼럼을 조회해서 바인딩할 경우)
- DTO를 만들어서 바인딩할 경우
SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m
**new 연산을 사용해서 DTO에 바인딩 할 수 있으면, 패키지 명을 포함한 클래스 명 전체를 입력해야 한다.
페이징API
페이징은 방언마다 지원하는 방시이 조금씩 다른데 예를 들면 오라클DB는 ROW NUM으로 구현하고 MYSQL의 경우 LIMIT로 구현한다. 그렇지만 JPA에서는 다양한DB의 페이징 방법을 추상화해 API로 지원하고 있으므로 매우 쾌적하게 페이징을 할 수가 있다.
- setFirstResult(int startPosition) : 조회 시작 위치 (0부터 시작)
- setMaxResults(int maxResult) : 조회할 데이터 수
구현한 코드를 보면
//페이징 쿼리
String jpql = "select m from Member m order by m.name desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(10) //조회를 시작할 위치
.setMaxResults(20) //조회할 데이터의 수
.getResultList(); // 리스트로 반환되고 10번부터 20개의 데이터가 반환됨
조인
JPQL의 조인은 3가지가 있는데, INNER JOIN, OUTER JOIN, 세타조인이 있다.
INNER JOIN과 OUTER JOIN이 외래키를 이용한 조인이라면 세타조인은 아무 연관이 없는 테이블 2개를 연결시키는 조인이다.
- 내부 조인:
SELECT m FROM Member m [INNER] JOIN m.team t
- 외부 조인:
SELECT m FROM Member m LEFT [OUTER] JOIN m.team t
- 세타 조인:
select count(m) from Member m, Team t where m.username= t.name
**FROM절에 테이블 두개를 넣고 WHERE로 조건을 맞춤 이거슨… 세타조인
그리고 JPQL은 조인과 동시에 필터링을 할 수 있는데
JPQL: //조인을 하고 바로 필터링
SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'A'
SQL: //조인을 하고 AND를 붙여서 필터링
SELECT m.*, t.* FROM
Member m LEFT JOIN Team t ON m.TEAM_ID=t.id and t.name='A'
서브쿼리
JQPL서브쿼리 예제 코드
//나이가 평균보다 많은 회원
select m from Member m
where m.age > (select avg(m2.age) from Member m2)
//한 건이라도 주문한 고객
select m from Member m
where (select count(o) from Order o where m = o.member) > 0
서브쿼리에서 지원하는 함수:
- [NOT] EXISTS (subquery): 서브쿼리에 결과가 존재하면 참
- {ALL | ANY | SOME} (subquery)
- ALL 모두 만족하면 참
- ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참
- [NOT] IN (subquery): 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
조건식 CASE
CASE를 이용해서 JPQL쿼리에 조건식을 넣을 수도 있다.
//기본 CASE식
select
case
when m.age <= 10 then '학생요금'
when m.age >= 60 then '경로요금'
else '일반요금'
end
from Member m
//단순 CASE식
select
case t.name
when '팀A' then '인센티브110%'
when '팀B' then '인센티브120%'
else '인센티브105%'
end
from Team t
JPQL에서 제공하는 CASE식 함수는 COALESCE와 NULLIF가 있다
- COALESCE: 하나씩 조회에서 NULL이 아니면 반환
- NULLIF: 두 값이 같으면 NULL반환, 다르면 첫번째 반환
// 사용자 이름이 없으면 이름 없는 회원을 반환
select coalesce(m.username,'이름 없는 회원') from Member m
// 사용자 이름이 ‘관리자’면 null을 반환하고 나머지는 본인의 이름을 반환
select NULLIF(m.username, '관리자') from Member m
JPQL 함수(기본함수/ 사용자 정의 함수)
기본함수:
- CONCAT
- SUBSTRING
- TRIM
- LOWER, UPPER
- LENGTH
- LOCATE
- ABS, SQRT, MOD
- SIZE, INDEX(JPA 용도)
등이 있고 자세한 내용은 https://en.wikibooks.org/wiki/Java_Persistence/JPQL#Functions 참조!
사용자 정의 함수
사용자가 함수를 정의해서 사용할 수 도 있는데, 사용하는 DB방언을 상속받아서 사용자 정의 함수를 등록하고 사용해야 한다.
경로 표현식)
점(.)을 찍어서 그래프 탐색을 하는 것을 경로 표현식이라고 한다. 경로 표현식의 용어를 좀 설명해 보자면:
- 상태 필드(state field): 단순히 값을 저장하기 위한 필드(ex: m.username)
- 연관 필드(association field): 연관관계를 위한 필드
단일 값 연관 필드: @ManyToOne, @OneToOne, 대상이 엔티티(ex: m.team)
컬렉션 값 연관 필드: @OneToMany, @ManyToMany, 대상이 컬렉션(ex: m.orders)
연관 필드의 경우 JOIN을 걸지 않더라도 묵시적(자동)으로 조인되어진다.(하지만 어떤 쿼리가 나올지 모르기 때문에 조인이나 페치조인을 사용하는걸 권장함)
경로표현식의 특징:
- 상태 필드(state field): 경로 탐색의 끝, 탐색X
- 단일 값 연관 경로: 묵시적 내부 조인(inner join) 발생, 탐색O
- 컬렉션 값 연관 경로: 묵시적 내부 조인 발생, 탐색X
FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
예를 들면, select m.username from Team t join t.members m (m별칭을 사용해서 m.username으로 탐색 가능)
페치조인)
페치조인은 성능 최적화를 위해서 자주 쓰이며 즉시로딩처럼 연관된 엔티티나 컬렉션을 SQL 한번에 같이 긁어오는 기능을 한다.
페치조인 문법:
- INNER JOIN FETCH +조인 경로
- LEFT OUTER JOIN FETCH +조인 경로
예제코드를 보면
//[JPQL]
select m from Member m join fetch m.team
그러나, 일대다 관계에서 페치조인을 할 경우 DB의 특성상 중복이 발생하게 되는데

그림과 같이 중복이 발생할 수밖에 없다.
그럼 중복문제를 해결하기 위해선? – DISTINCT를 사용하자!
DISTINCT를 사용하면 select distinct t from Team t join fetch t.members where t.name = ‘팀A’
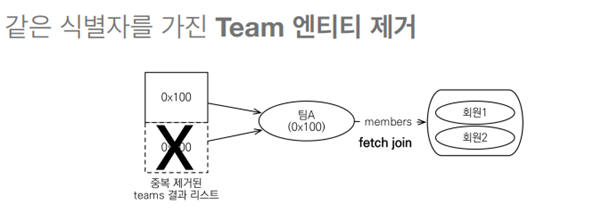
페치조인 VS 일반조인
- 일반조인
select m from Member m join fetch m.team
**조인은 되지만 m.team 을 조회할 수 가 없다. 직접 m.team을 SELECT절에 넣어 주어야 한다.
- 페치조인
select m from Member m join fetch m.team
** m.team으로 접근이 가능하다.
페치조인의 한계는:
- 페치조인 대상에는 별칭X
select m from Member m join fetch m.team t 페치조인 별칭X,
select m, t from Member m join m.team t 일반조인 별칭 가능
- 둘 이상의 컬렉션은 페치조인 할 수가 없음.
- 페치조인은 페이징을 API를 사용할 수가 없음.
**이유는 페이징으로 긁어오면 컬렉션에 남은 결과가 있음에도 잘려버리기 때문에 장애로 발전될 가능성이 매우 높음
-
**쿼리가 너무 복잡해질 경우 페치조인보다 조인을 써서 DTO에 담아 내는게 더 적합하다.
다형성 쿼리)
엔티티 직접 사용)
COUNT()와 같은 집계 쿼리나 WHERE절에 파라미터로 엔티티를 전달할 경우 SQL변환과정에서 ID식별자로 변환되니 객체를 직접 사용해도 된다 team t == t.id
Named 쿼리)
미리 이름을 정의해 두고 사용하는 JPQL로 어노테이션에 적용할 수 있다. 또한, 어플리케이션 로딩 시점에서 초기화 된 후 사용되기 때문에 잘못 작성된 쿼리라면 로딩시점에 감지할 수 있다는 장점이 있다.
NAMAED쿼리 예제코드
@Entity
@NamedQuery(
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username",
"회원1")
.getResultList();
만약 XML에 정의할 경우 META-INF/persistence.xml에
<persistence-unit name="jpabook" >
<mapping-file>META-INF/ormMember.xml</mapping-file>
라고 적고
META-INF/ormMember.xml에
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm" version="2.1">
<named-query name="Member.findByUsername">
<query><![CDATA[
select m
from Member m
where m.username = :username ]]>
</query>
</named-query>
<named-query name="Member.count">
<query>select count(m) from Member m</query>
</named-query>
</entity-mappings>
벌크 연산)
벌크 연산의 특징:
- 쿼리 한번으로 여러 테이블 로우 변경 가능
- executeUpdate()는 영향을 받은 엔티티의 수를 반환
- UPDATE, DELETE 지원
- 하이버네이트의 경우 INSERT(INSERT INTO… SELECT…)지원
예제코드
String qlString = "update Product p " +
"set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(qlString)
.setParameter("stockAmount", 10)
.executeUpdate();
벌크 연산시 주의점
벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리를 날리는 것이기 때문에
- 벌크연산 실행후 영속성 컨텍스트 초기화
- em.clear();
'Programming > JPA' 카테고리의 다른 글
| [JPA] 값 타입 (0) | 2021.01.24 |
|---|---|
| [JPA] 엔티티매핑 (0) | 2021.01.24 |
| [JPA] 고급 매핑 - 3 (0) | 2021.01.23 |
| [JPA] 다양한 연관관계 매핑-2 (0) | 2021.01.23 |
| [JPA] 연관관계 매핑 기초 - 1 (0) | 2021.01.23 |



